国际著名学术期刊《Transportation Research Part C: Emerging Technologies》2024年10月刊发表了我院学者的论文《基于推理图强化学习的人机混驾无信号交叉口协同方法》(Reasoning Graph-based Reinforcement Learning to Cooperate Mixed Connected and Autonomous Traffic at Unsignalized Intersections)。博士生周东浩为第一作者,孙剑教授为论文的通讯作者,杭鹏副教授为第二作者。

Zhou D, Hang P, Sun J. Reasoning graph-based reinforcement learning to cooperate mixed connected and autonomous traffic at unsignalized intersections[J]. Transportation Research Part C: Emerging Technologies, 2024, 167: 104807.
文章摘要
在智能网联车(Connected and Automated Vehicle, CAV)和人类驾驶车(Manually-driving vehicle, MV)共存的人机混驾环境中,实现无信号交叉口的协同可有效提高交叉口系统的安全、效率和节能表现。但是,人机混驾交通流也带来了诸多挑战,包括:人类驾驶车行为的不确定性、复杂交互链式反应的多样性等。为解决上述问题,本文基于情景优化的协同思路,提出了基于推理图的强化学习(RGRL)方法。首先,基于交互图绘制双向边将当前驾驶场景表示为抽象情景。此过程被构建为基于推理图的马尔可夫决策过程,通过逐步推断车辆通行序列,从而按顺序描绘整个情景。然后,提出了一种基于图神经网络的策略网络,使用图卷积网络捕捉相互关联的车辆连锁反应,并使用图注意力网络来衡量多样化互动的关注度。此外,还开发了环境模块用于策略训练,该模块包括CAV和MV轨迹生成器,提供了考虑社会适应性、避免碰撞、效率和节能的奖励函数。最后,实施了三种强化学习方法,D3QN、PPO和SAC进行比较测试以探索该框架的适用性和优势。测试结果表明,D3QN在收敛奖励上优于其他两种方法,同时保持了类似的收敛速度。与多智能体强化学习(MARL)相比,RGRL方法在统计上表现出更优的性能,减少了77.78%至94.12%的严重冲突数量。在中等或高市场渗透率下,RGRL将平均和最大行程时间减少了13.62%至16.02%,燃油消耗减少了3.38%至6.98%。此外,基于硬件在环(HIL)和车辆在环(VehIL)实验中进一步验证了模型的有效性。
研究贡献
(1) 提出了RGRL框架,将情景推理过程表述为基于推理图的马尔可夫决策过程(MDP),结合了推理图在解决多模态决策问题方面的优势和强化学习(RL)在实时决策中的优势,实现在爆炸性增长的情景解空间中求解最优情景。
(2) 将图神经网络(GNN)与图推理过程相结合,有效捕捉多交互链式反应的特征,减少了决策过程中的不确定性。
(3) 利用图卷积网络(GCN)模拟链式反应的机制,其中每辆车的行为通过节点特征来表征,特征信息可在交互车辆间传递。研究使用图注意力网络(GAT)确定注意力系数,用以捕捉交互车辆的不同状态和类型的交互强度。
研究背景
无信号交叉口一直被认为是城市交通的瓶颈,造成了约30%的交通事故和20%的致死事故。无信号交叉口主要难点问题在于多种类、多流向的冲突的耦合,存在交互数量多、类型多样且分布广泛的特征。自动交叉口管理(Autonomous Intersection Management, AIM)通过引入纯CAV实现冲突消解。然而,在CAV和MV共存的混合交通流环境中,关注纯CAV环境下的AIM方法可能在混驾交通流环境中导致CAV的“不合群”,这些行为不仅破坏了交通系统的效率,还引发了交通堵塞、其他驾驶员的路怒、甚至是事故风险。因此,实现人机混驾下的多冲突混驾流协同是一个亟需解决的问题。
多冲突混驾流协同存在如下技术难点。首先,MV行为的不确定性导致意图和轨迹的多种可能性,导致了多模态行为模式,多冲突的混驾流进一步放大了这种不确定性,如何实时地应对这些模态变化是难点之一。第二,无信号交叉口内的多交互作用,会引发一系列链式反应,众多相互关联的链式反应形成链式反应网络,即使是车辆行为的细微变化也可能对其他车辆产生深远影响,使描述和追踪某车行为产生的后续影响变得十分困难。第三,每辆CAV必须同时与不同运动状态的车辆交互,不同交互对本车的影响程度是不同的,如何衡量对不同交互的关注程度也是一个难点。
现有研究尝试使用规则、优化或强化学习方法来解决这个问题。然而,很少有研究考虑了交互不确定性耦合链式反应带来的难点, MV的不确定性会通过链式反应网络在系统全局范围内传播,仅通过制定规则或通过顺序的马尔可夫决策过程难以捕捉系统层面的不确定性。
研究内容
(1)基于交互图表征潜在情景
由于车辆之间的部分交互关系存在较大不确定,本文提出基于有向图的交互图表达形式,描述当前场景的交互情况和意图的不确定性。每个节点代表一辆车,边的方向表示从先行车指向后行车的先后行关系。跟驰交互对应物理先后关系,可通过观察车辆的先后顺序直接确定,采用单向边表示。冲突交互对应逻辑先后关系,其先后行关系体现在异向冲突下的抢行或让行行为导致的先后行,由于不可通过观察或测量当前车辆运动状态确定,而是和车辆的意图相关,存在多可能性,采用双向边表示。逻辑交互关系常见于合流和穿越场景等多交互场景中,各交互参与者对每个交互对象存在多个潜在的交互意图,这导致了情景的多样性。
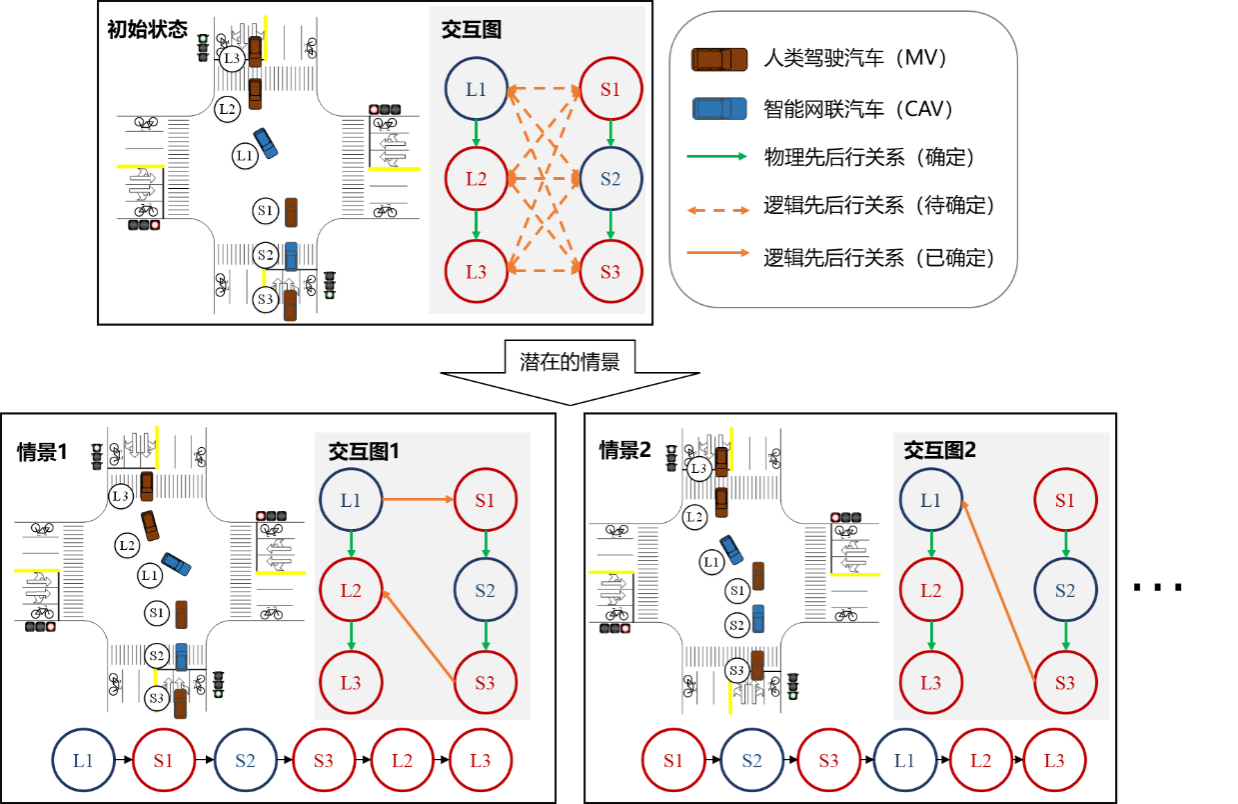
情景的交互图表征
(2)基于推理图的马尔科夫决策过程
多冲突混驾流下的CAV协同问题同样可以描述为上述序贯决策过程。将搜索过程中半确定的交互图作为当前状态,其中节点为各车运动状态的集合,边为车间确定和待确定的交互关系的集合。通过交互图表现多维信息特征,包括各车历史和当前运动状态、交互意图、先后行关系、未来运动的相互影响关系等。然后,将四个进口道的通行权作为动作空间,组成如图所示马尔科夫决策过程。
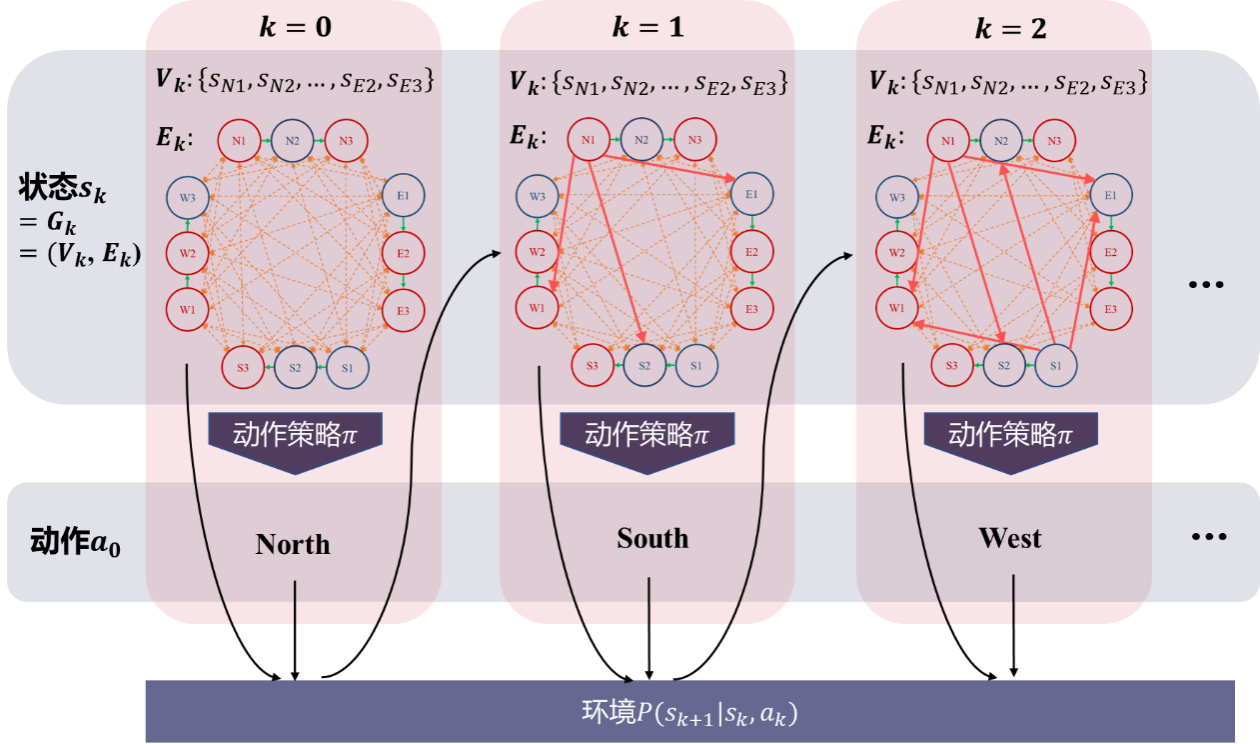
基于推理图的马尔科夫决策过程示例
(3)基于推理图的深度强化学习框架
基于上述马尔科夫决策过程,提出基于交互图的深度强化学习(Deep Reinforcement Learning, DRL)总体框架。首先通过交互图来描述场景包括每辆车的运动状态以及它们之间的交互关系。第k个阶段的状态除了包含此交互图外,还包括序列特征。将此阶段的状态输入策略网络,即可得到该阶段的动作和阶段特征。将动作输入环境模块,环境定位到动作指定的流向中已获得通行权车辆后的第一辆车作为目标车,找到目标车的跟驰前车,逻辑前车和后车。根据本车和逻辑后车的运动状态,判断本车抢行该车是否符合人类预期,并规划局部轨迹,最后基于本车的轨迹计算效益并输出。
智能体基于当前状态来确定动作。环境模块一方面根据当前状态产生下一步的状态,另一方面生成奖励引导策略更新,促使策略选出在长期内产生高累积奖励的动作,最终目标是提高交叉口的整体效益。
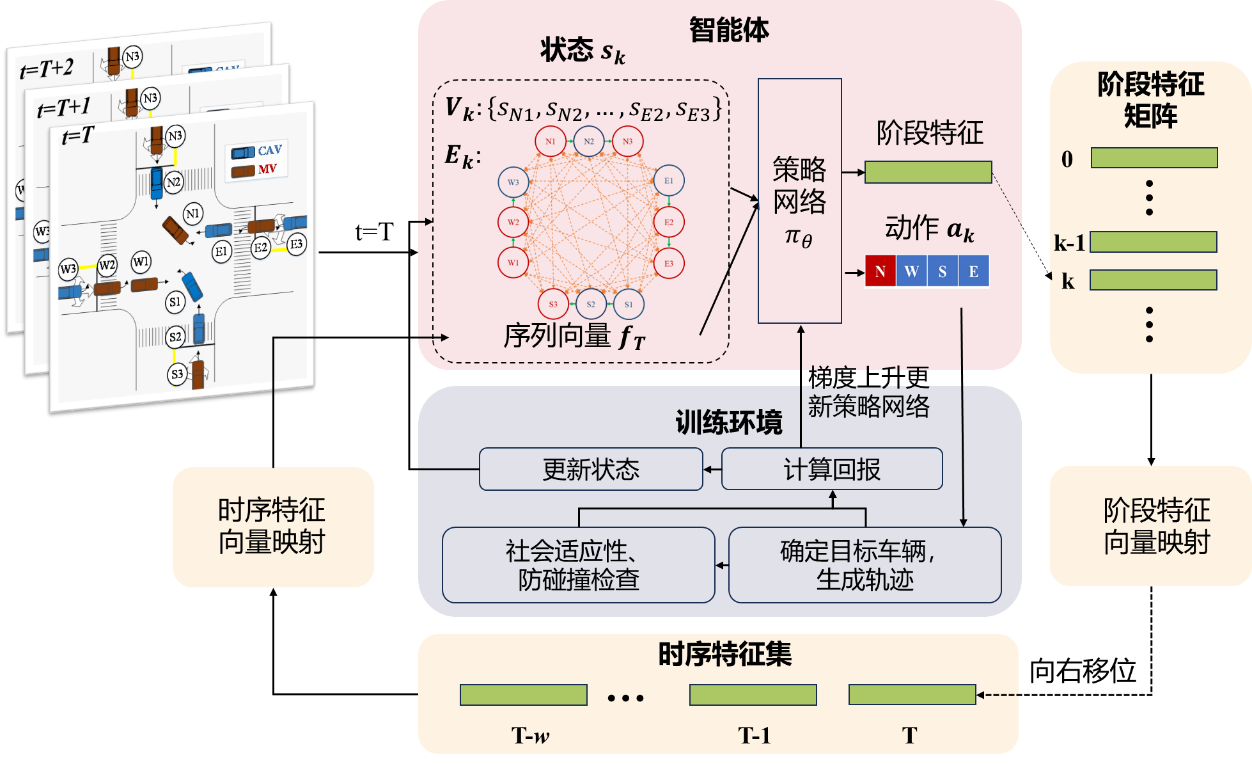
基于交互图的强化学习框架
(4)动作策略网络结构
采用图神经网络(Graph Neural Network, GNN)实现图特征的提取。其中图卷积网络的信息传递方式完全模拟了链式反应中交互影响链式传递的过程,十分适合在复杂交互且存在链式反应的系统中的特征提取。引入了图注意力层异质的考虑不同节点状态对本节点造成的影响。
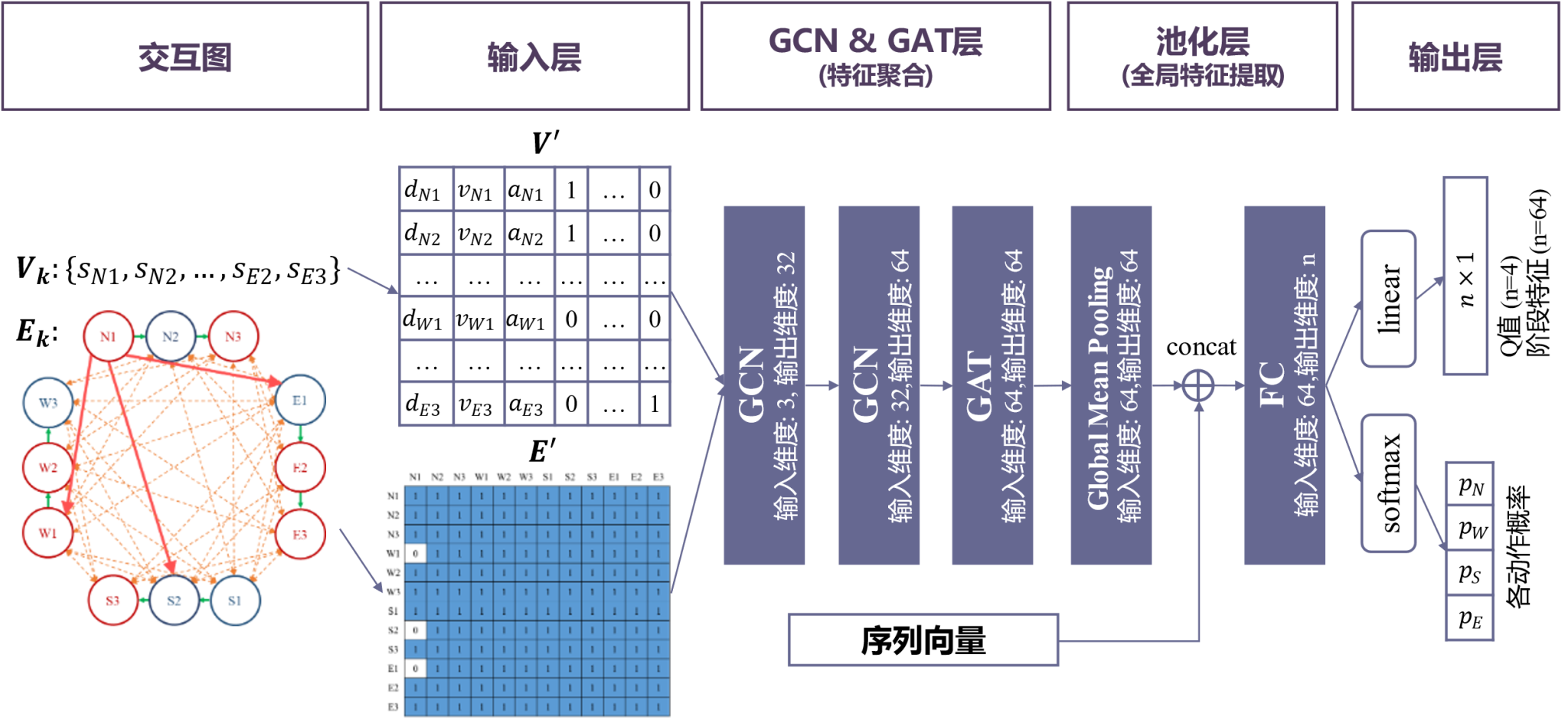
基于GNN的动作策略网络结构
(5)环境模块和动作策略网络学习
在环境模块中,基于五次样条曲线计算车辆轨迹,并基于轨迹计算车辆的安全、效率、能耗表现,加权求和作为奖励值返回,用以更新动作策略网络。训练动作策略网络时,同时实现了三种广泛使用的策略学习方法D3QN,PPO和SAC,对比确定最优更新算法。
实验结果
(1)仿真实验
仿真实验中,选择多智能体强化学习(MARL)和经典基于优化(Optim)的方法。为了评估此方法在不同CAV市场渗透率(Market Penetration Rate, MPR)下的表现,设置了五个不同的MPR组别。结果显示,与MARL系统相比,RGRL系统中严重冲突的出现频次较少,RGRL系统的行程时间减少了0.46%至16.02%不等,平均能耗在高渗透率下减小6%以上。
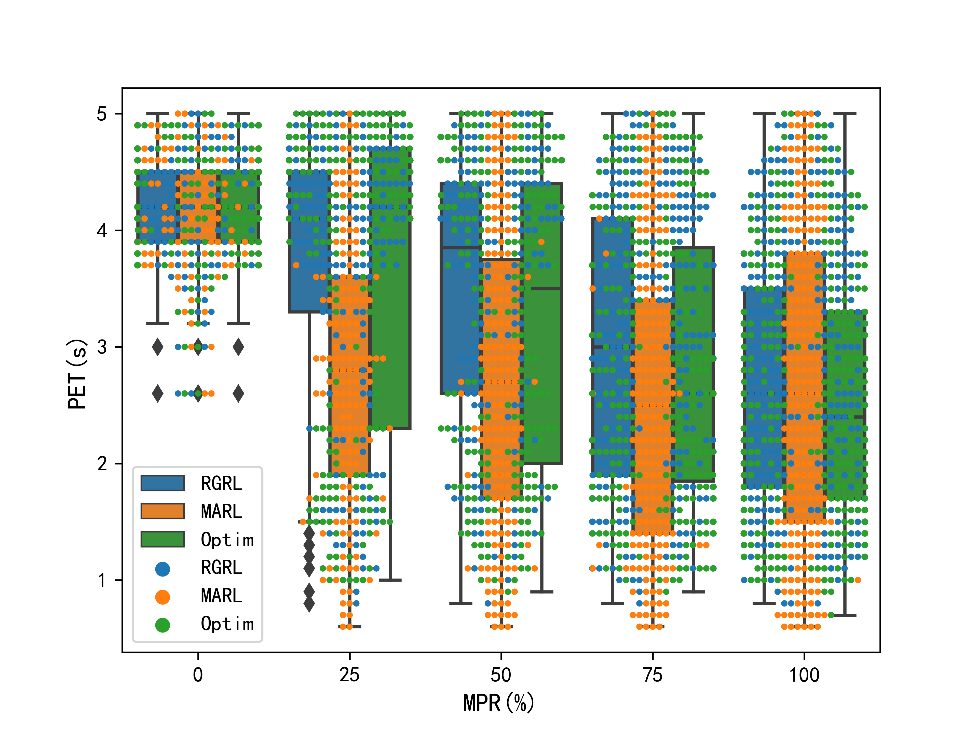
(2) 硬件在环(HIL)实验
硬件在环测试平台框架如图所示。实验平台表现上,90.7%的最大控制误差小于1%,99.3%的最大控制误差小于1.5%,84.0%的通信时延小于0.02s,98.1%的通信时延小于0.03s。协同方法的运算时间上,4辆车参与协同时90%计算时间小于20.4%,6辆车参与协同时90%计算时间小于30.9%,8辆车参与协同时90%计算时间小于44.6%。此外,与其他方法相比,RGRL在大行程时间(>20s)和大燃油消耗出现频次更少。
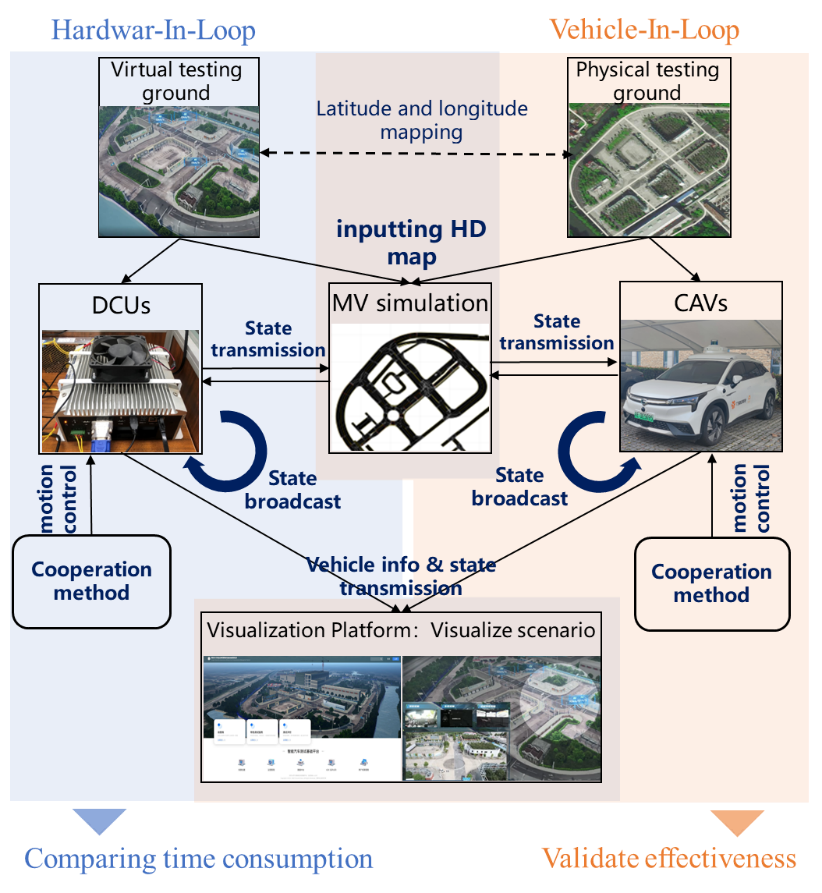
硬件在环、车辆在环实验平台
(3)车辆在环(VehIL)实验
在同济大学测试场选择了一个典型的十字路口作为研究地点,设计了一个典型场景,涉及3辆智能网联实车(CAVs)和8辆虚拟的人类驾驶车。结果表明,多辆CAV可安全有序地通过冲突区域。MV的操作是由仿真软件驱动的,对CAV是黑盒,所提方法能够适应MVs行为中的不确定性,实现了交叉口的安全有序通行。

改装的智能网联车

实车实验