因疫情防控工作需要,为快速有效阻断病毒传播链,同济大学采取疫情防控动态管控模式,其中核酸检测工作已经成为大家的日常。
刚开始的几天,按照学院要求,每位同学在做完核酸后,需要按时上交采样的截图,结果出来后,也需要上交检测结果的截图。由于核酸检测较为密集,且每次核酸结果出来时间长短不一,导致很多同学上传了错误的截图。有的同学将本该上传的核酸检测结果图上传成了核酸检测图,有的同学看错了采样时间和检测时间,上传了上次的核酸检测结果。
为了确保上传结果的正确性,每天班委、年级助管和学工口老师都需要花费大量的时间来逐一核查图片,将上传错误的同学挑出来,告诉错误原因并重新上传。这给大家增加了不小的工作负担。
教师党员黄世泽副教授在和同学的交流中得到了这个信息以后,提出可以借助团队的科研积累,运用专业知识为师生做点儿事情,提升统计检测结果的效率。团队的研究方向为交通信息可信感知,对视频和图像的处理是团队每位成员的基本功。对于该问题,如果利用OCR对图片进行识别,应该能够解决问题。
2022年4月8日20:00,黄世泽老师紧急组建了项目团队,包括团队2018级交通工程本科生2名、2020级硕士研究生1名和2021级硕士研究生1名。当晚,黄世泽老师主持团队第一次会议,不到24小时,该系统成功上线,实现了预先设定的功能。
4.8-20:30
团队第一次会议,明确分工
团队从程序的需求、开发、封装到测试进行逐一讨论,最终确定分工为:2018级本科生李星颖负责项目的需求分析,2020级张兵杰负责项目的核心算法开发,2021级硕士研究生宋冠群负责对项目的封装和优化,2018级本科生张毅负责系统的测试和优化。会议同时初步明确了系统的基本功能,明确了项目的技术路线,同时对应用可能存在的问题进行了讨论,并探讨了未来进一步的优化方向。
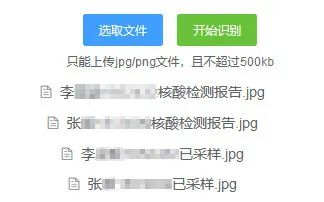
4.8-23:00
完成项目的需求分析
了解到各班班长和年级助管需要核对采样时间、采样者姓名、检测结果等,根据其工作内容,团队确定了初步的应用需求,即通过上传图片到程序中,实现图片路径、采样类别、姓名、采样时间、检测结果信息的输出。
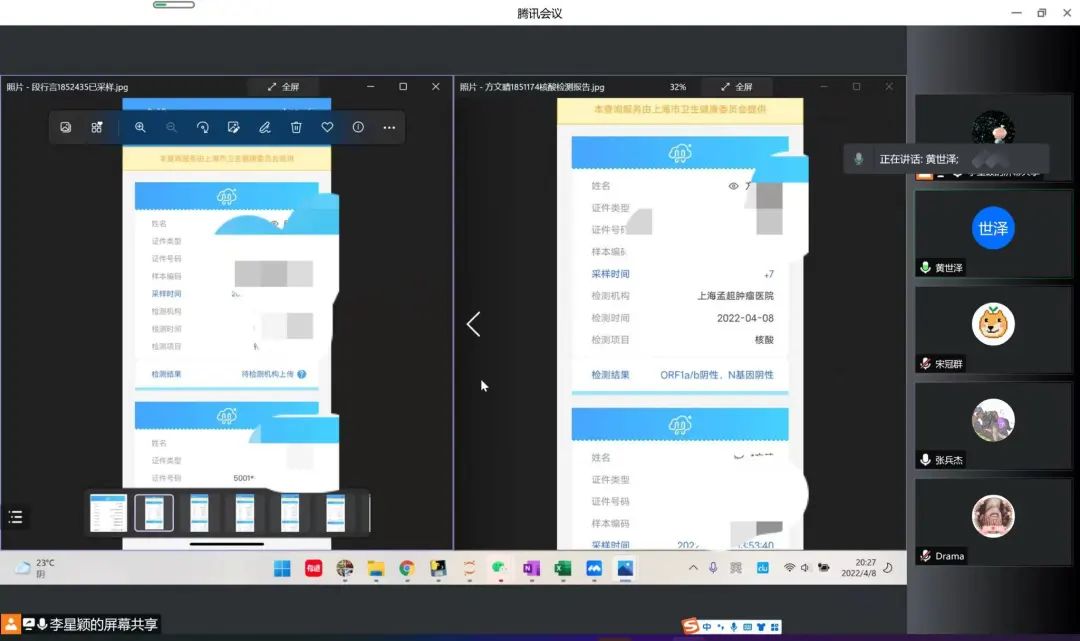
4.9-16:00
完成项目的核心代码开发
团队开发思路如下:
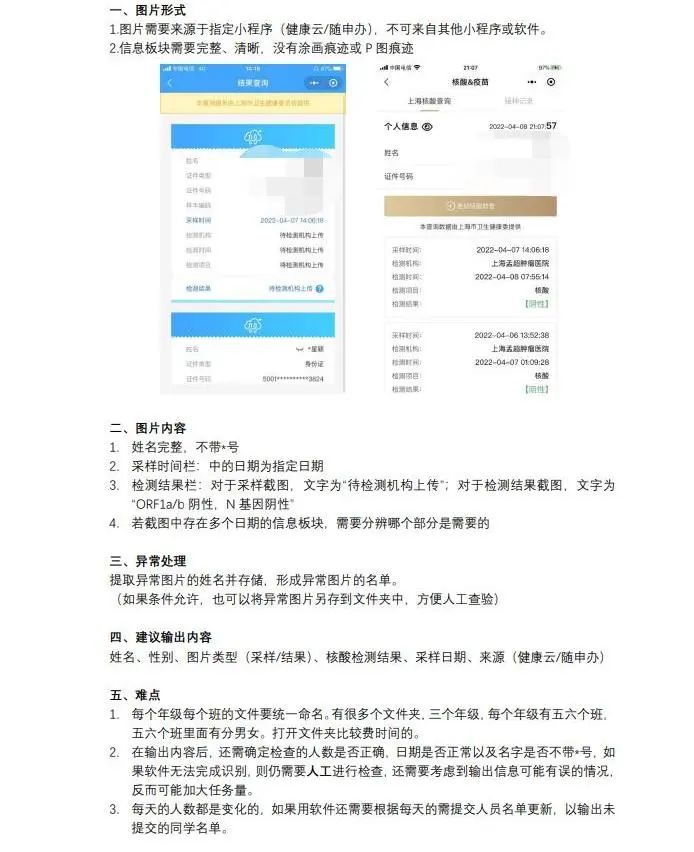
1、接收来自前端的截图文件列表。用户在页面批量选取上传核酸检测截图文件,前端通过请求将这些文件发送给本地后端,后端服务器接收并进行下一步的识别处理。
2、读取图片信息。批量读取用户所选取的截图文件,调用OCR识别模型识别每张图片的文字信息存放为字符列表,根据需要记录的信息,在字符列表中进行匹配和分类,若成功获取所有信息且检测结果为阴,把匹配后的结果存入正常检测列表;否则,存入异常检测结果列表。
3、结果输出。输出为表格,根据检测结果列表,逐行输入图片路径,图片类型(采样/检测),姓名,采样时间,检测结果的信息。存储为XLS格式的表格。如果存在异常检测结果,则输出异常检测列表。
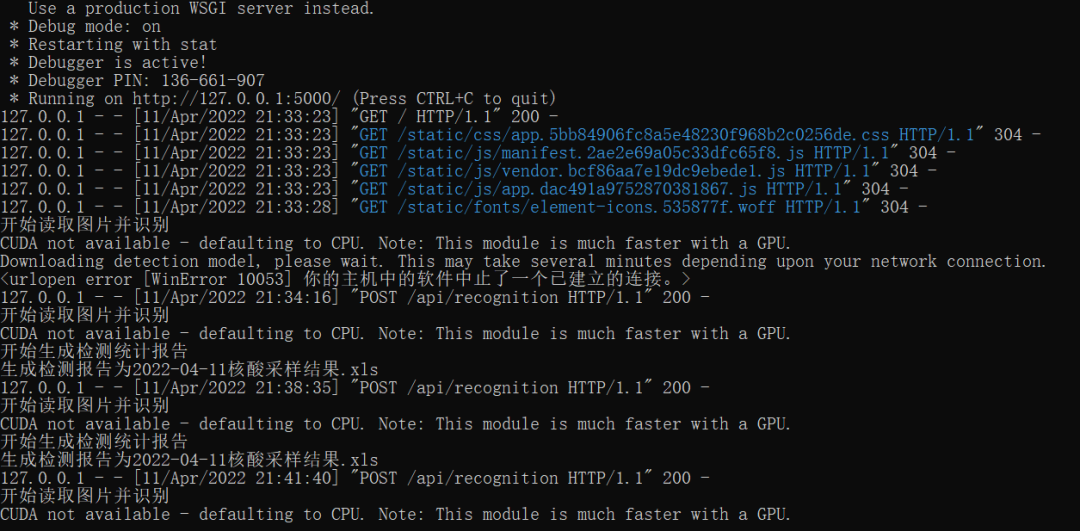
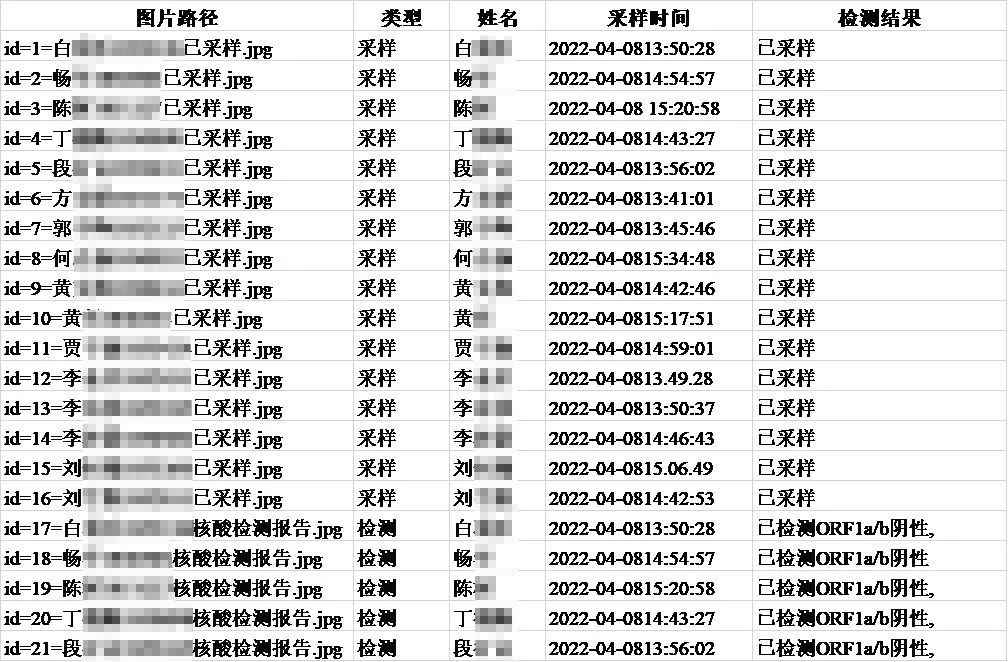
4.9-20:00
完成程序封装
前端页面使用Vue.js框架实现,利用Element组件库,创建了批量上传核酸检测图片的用户界面,在用户点击“开始识别”按钮后,页面发起请求,并将文件列表传递给后端。在后端逻辑上,基于实现好的OCR脚本,稍加修改并暴露所需调用的函数,采用Flask框架作为本地服务器,响应页面请求并启动识别进程。整个项目代码在Python环境下进行简单配置,即可在本机上复现运行。打开浏览器访问本地端口便能选取文件进行识别,识别结果将以Excel文件形式自动导出至项目目录下。